-
[Java]서로소 집합(Disjoint Set)(Union-Find)(Merge-Find Set)Algorithm/자료구조 for Algorithm 2021. 4. 15. 11:08
*서로소 집합(Disjoint Set)
-> 서로소 집합 자료구조는 상호 배타적으로 이루어진 집합(서로소 집합 : 공통 원소가 없는 두 집합)을 효율적으로 표현하기 위해 만들어진 자료구조이다.
-> 서로소 집합은 서로 다른 두 개의 집합을 병합하는 연산(Union)(Merge)과 집합의 원소가 어떤 집합에 속해 있는지 판단하는 연산(Find)을 기반으로 구현되기 때문에, Union-Find 혹은 Merge-Find Set이라고도 불린다.
-> 서로소 집합을 구현하는 방법은 연결 리스트를 이용하는 방법과, 트리를 이용하는 방법이 있는데, 이 글에서는 트리를 이용하는 방법에 대해서만 다룬다.
*서로소 집합의 단순 구현(트리)
-> 서로소 집합은 기본적으로 총 3가지 연산(MakeSet, Find, Union)으로 구성되어 있다.
(1) MakeSet 연산 : 대상 원소들을 우선 모두 각각 독립된 집합으로 분리하는 과정이다. 서로소 집합은 대상 원소가 각각 어떤 집합에 포함되어 있는지 번호를 주어 표시한다. 우선 처음 주어지는 원소들은 따로 집합이 정해져 있지 않기 때문에, 자기 자신의 원소 번호를 자신이 속해있는 집합으로 초기화하는 과정이라고 생각하면 된다. 앞으로 1, 2, 3, 4, 5원소를 기준으로 예를 들어 서로소 집합을 구현해보도록 하겠다.
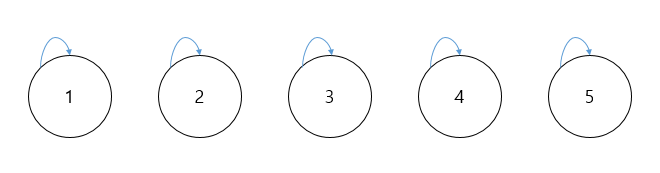
초기 원소는 자기 자신의 번호를 자신이 속한 집합이라고 인식한다. 자기 자신이 가리키는 대상 = 자신이 속한 집합이 되기 때문에, 자기 자신이 가리키는 대상을 parent(부모)라고 표현하기도 한다. 이를 바탕으로 코드를 구현하면 다음과 같다.
import java.util.Arrays; public class DisjointSet { public static void main(String[] args) { int[] parent = MakeSet(5); // 각 인덱스(=노드)는 자기 자신을 가리키고 있다 System.out.println(Arrays.toString(parent)); } private static int[] MakeSet(int size) { // 각 인덱스에 번호가 대응하도록 사이즈를 1더하여 배열 선언. int[] arr = new int[size + 1]; for (int i = 0; i < arr.length; i++) { arr[i] = i; } return arr; } }
결과 (2) Union 연산, Find 연산 : 다음은 서로소 집합을 하나의 집합으로 합쳐주는 연산인 Union 연산과 대상 원소가 어떤 대상을 가리키는지, 즉 어떤 집합에 포함되어 있는지(부모가 누구인지)를 파악하는 연산인 Find 연산을 구현해보자. 두 연산은 구현 상에서 서로 밀접한 관계가 있기 때문에, 동시에 이해하는 것이 낫다.
-> 먼저 Union 연산을 살펴보자. 서로 다른 두 원소를 같은 집합으로 포함시키기 위해서는 어떤 방법을 사용할까? 정답은 두 원소가 모두 같은 부모(parent)를 가리키도록 값을 변경해주면 된다. 이 경우 보통 두 원소중 작은 값을 기준으로 가리키는 부모를 통일 시켜준다(자세한 내용은 뒤의 최적화와 관련된 내용 참고!). 이를 테면 원소 1, 2를 같은 집합으로 속하게 만들고 싶다면 아래와 같은 그림이 될 것이다.
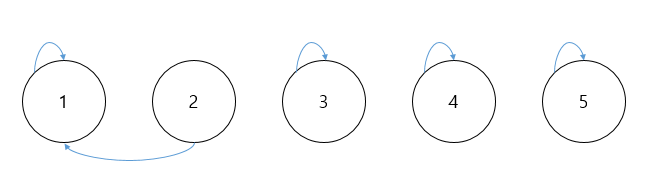
1, 2가 같은 집합에 속해있다면, 원소 2는 1을 부모로 가리켜야 한다. 그림과 같은 상황이라면, 각 원소는 {1, 1, 3, 4, 5}와 같은 형태로 가리키는 대상이 설정되어 있을 것이다.
-> 위와 같은 상황을 이해하면, Find 연산을 구현하는 것은 쉽다. 찾고자 하는 원소가 자신의 인덱스 값과 같다면, 즉 자기 자신이 부모인 상황이라면 그 값이 그 집합을 대표하는 번호일 것이다. 그렇지 않다면, 지금 원소가 가리키는 값을 재귀적으로 다시 Find 함수에 넘겨주어 부모 노드까지 탐색을 하면 된다. 즉, 재귀함수를 이용하여 구현할 수 있다.
private static int find(int[] parent, int x) { // 만일, 찾는 대상과 인덱스 번호가 같다면 그 인덱스(=노드)가 해당 집합의 부모이다. if(parent[x] == x) return x; // 그렇지 않다면, 해당 인덱스가 가리키는 값(부모 노드)을 따라 최종 부모노드까지 탐색한다. else return find(parent, parent[x]); }-> Find 연산을 구현했으니, 이제 Union 연산을 구현하면 될 것 같지만 한가지 주의할 점이 있다. 그것은 Union 연산은 서로 다른 '두 집합'을 합치는 연산이라는 것이다. 예를들어 지금까지의 논리로 앞서 만든 집합의 상태에서 3을 1, 2의 집합에 포함시키고, 4, 5를 또 다른 집합으로 만들었다고 가정해보자. 그렇다면 다음과 같은 그림이 될 것이다.
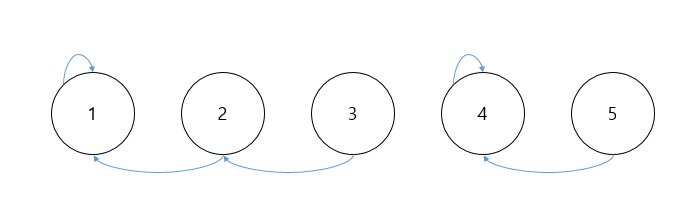
원소 1, 2, 3이 같은 집합이고 4, 5가 같은 집합이다. 그렇다면 이 상태에서 원소 3, 5를 이용하여 두 집합을 합치는 경우 다음과 같은 실수를 범해서는 안된다.
private static void union(int[] parent, int a, int b) { // 각 대상이 가리키는 부모를 구한다. int o1 = find(parent, a); int o2 = find(parent, b); // 부모가 작은 쪽으로 흡수해야 하므로 분기문을 나눈다. if (o1 > o2) { // a원소의 부모를 b원소의 부모로 바꾼다. parent[a] = o2; } else { // b원소의 부모를 a원소의 부모로 바꾼다. parent[b] = o1; } }이렇게 하게 된다면 원소 5에 대해서만 3이 포함된 집합의 부모를 가리키게 된다. 즉 다음과 같은 그림의 상황이 된다.
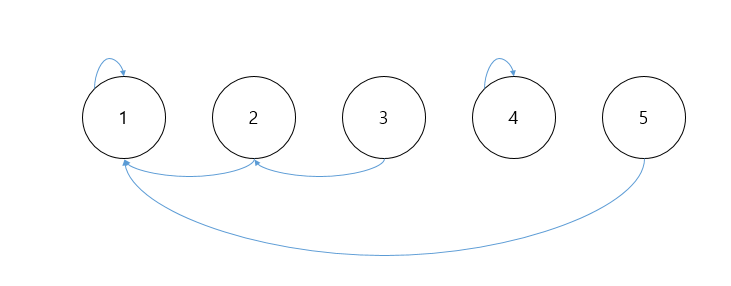
두 집합이 합쳐진 것이 아니라, 원소만 해당 집합으로 편입 되었다. 서로소 집합에서 '합치기 연산'은 앞서 말했지만 '두 집합을 합치는 연산'이다. 따라서, 두 집합의 부모(대표자)가 다른 부모를 가리키도록 로직을 설계해주어야 한다! 그렇다면 아래와 같은 코드로 구현할 수 있을 것이고, 그림은 다음과 같은 것이다.
private static void union(int[] parent, int a, int b) { // 각 집합을 대표하는 부모가 다른 부모로 편입 되어야 한다. 원소가 편입되어서는 안된다. a = find(parent, a); b = find(parent, b); if (a > b) { parent[a] = b; } else { parent[b] = a; } }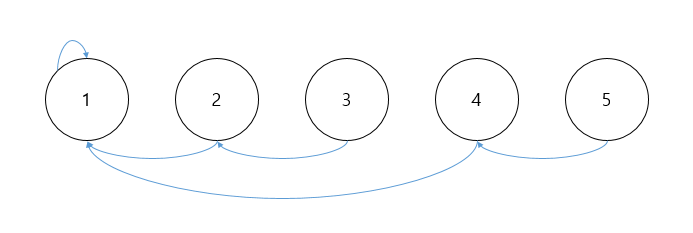
두 서로소 집합을 하나의 집합으로 합친 모습 이 모든 과정을 하나의 코드로 합치면 아래와 같고, 앞서 합친 순서대로 결과를 출력해보면 다음과 같을 것이다.
import java.util.Arrays; public class DisjointSet { public static void main(String[] args) { int[] parent = MakeSet(5); // 각 인덱스(=노드)는 자기 자신을 가리키고 있다 System.out.println(Arrays.toString(parent)); union(parent, 1, 2); System.out.println(Arrays.toString(parent)); union(parent, 2, 3); System.out.println(Arrays.toString(parent)); union(parent, 4, 5); System.out.println(Arrays.toString(parent)); union(parent, 3, 5); System.out.println(Arrays.toString(parent)); System.out.println(find(parent, 1)); System.out.println(find(parent, 2)); System.out.println(find(parent, 3)); System.out.println(find(parent, 4)); System.out.println(find(parent, 5)); } private static void union(int[] parent, int a, int b) { // 각 집합을 대표하는 부모가 다른 부모로 편입 되어야 한다. 원소가 편입되어서는 안된다. a = find(parent, a); b = find(parent, b); if (a > b) { parent[a] = b; } else { parent[b] = a; } } private static int find(int[] parent, int x) { // 만일, 찾는 대상과 인덱스 번호가 같다면 그 인덱스(=노드)가 해당 집합의 부모이다. if (parent[x] == x) return x; // 그렇지 않다면, 해당 인덱스가 가리키는 값(부모 노드)을 따라 최종 부모노드까지 탐색한다. else return find(parent, parent[x]); } private static int[] MakeSet(int size) { // 각 인덱스에 번호가 대응하도록 사이즈를 1더하여 배열 선언. int[] arr = new int[size + 1]; for (int i = 0; i < arr.length; i++) { arr[i] = i; } return arr; } }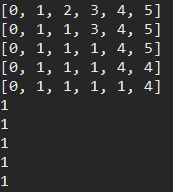
※ 알고리즘 문제 풀이시 주의점 : 여기서 parent 배열은 '각 원소의 부모'를 나타내는 것 뿐이지 각 원소가 실제로 어떤 집합에 속해있는지를 표현해주지 않는다. 각 원소가 어떤 집합에 속해있는지를 파악하기 위해서는 반드시 Find 연산을 사용해야만 한다.
*시간복잡도
-> 우선 기본적으로 Union 연산과 Find 연산을 살펴보면 Union 연산내에서 가장 큰 영향을 미치는 연산이 Find 연산임을 알 수 있다. 즉, Union 연산과 Find 연산의 시간 복잡도는 동일하다.
-> 트리의 원소가 편중되어 있는 형태라면, 매 연산마다 노드의 끝까지 탐색해야 되기 때문에 O(n)의 시간복잡도를 가지게 될 것이다.
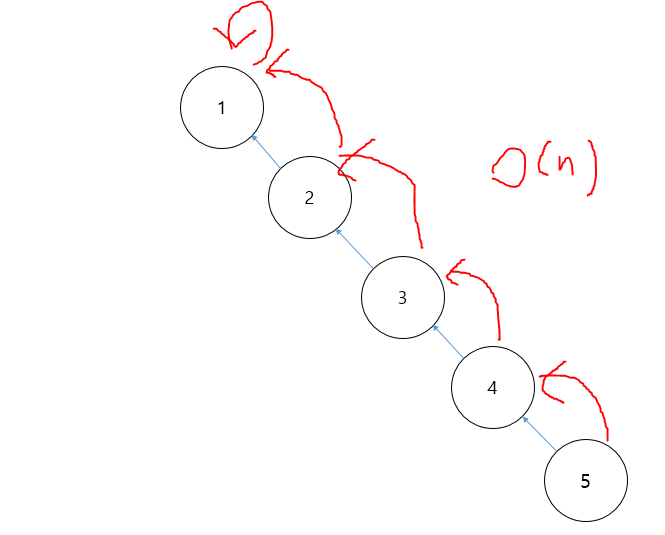
트리가 편중된 경우 *서로소 집합 최적화
-> 앞선 서로소 집합의 성능을 개선하기 위하여, Union 연산 혹은 Find 연산에서 각각 연산의 성능을 향상시키는 방법이 존재한다. 두 방법 중 하나를 선택하면 되지만, 보통 경로 압축(Path Compression)기법을 기반으로한 Find 연산에서의 최적화 방법을 자주 사용한다.
(1) Union 연산에서의 최적화(Union by Rank) : 두 집합을 서로 합치는 과정에서 아무런 기준없이 합치게 된다면 트리의 깊이가 깊어질 수도 있는 문제가 발생한다. 예를 들어, 원소 1, 2가 같은 집합이고 3, 4, 5가 같은 집합인 경우 1, 2 집합을 3, 4, 5 집합에 합치는 경우는 문제가 발생하지 않는다. 즉, 원소의 개수가 적은 집합이 많은 집합에 편입된다면 문제가 발생하지 않는다.
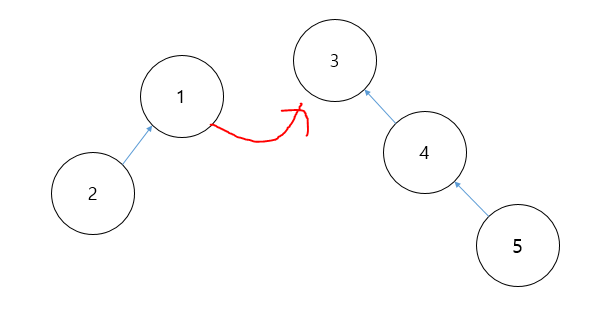
원소의 개수가 적은 집합이 흡수되는 경우 전체 트리의 깊이는 변화하지 않는다. 하지만 반대로 원소의 개수가 많은 집합이 적은 집합으로 편입된다면 트리의 깊이가 점점 깊어지는 문제가 발생한다.
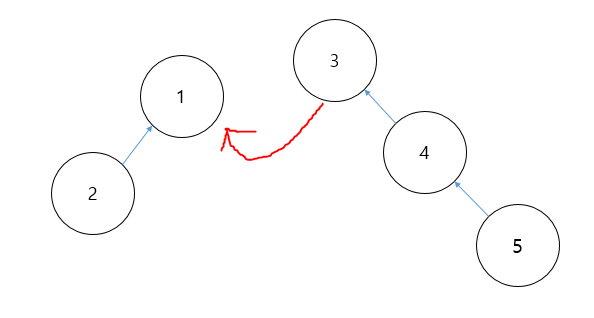
원소의 개수가 많은 집합이 흡수되는 경우 전체 트리의 깊이는 점점 커진다. 이렇게 깊이가 점점 깊어지면, Find 연산이 재귀의 형태로 이루어져 있으므로 Find 연산을 수행할 때 최악의경우 O(n)의 시간복잡도를 갖는다. 이를 해결하기 위하여 Rank를 이용한 Union 연산(Union by Rank)을 진행한다. 이 연산은 간단히 말하면, 기존에 두 집합을 합하는 과정에서 부모 노드의 번호가 작은 쪽으로 편입하는 대신, 각 집합의 크기(트리의 깊이)를 Rank라는 값으로 기억해두고 앞서 언급한대로 Rank가 더 큰 쪽으로 트리를 편입시키는 방법을 사용한다. 이 경우 시간 복잡도를 O(logN)까지 줄일 수 있다. 이 글에서는 Rank를 이용한 방법으로 따로 구현을 하지는 않겠다. 개념만 알아두도록 하자.
(2) Find 연산에서의 최적화(경로 압축 : Path Compression) : 앞서 Rank를 이용한 방법보다 구현이 더 쉽기 때문에 서로소 집합 연산의 성능을 향상 시킬때 자주 사용되는 방법이다. 이 방법은 Find 연산이 재귀의 형태로 구현된 점, 매 탐색마다 트리의 부모 노드까지 탐색하는 비효율을 방지한다는 두 가지 아이디어를 바탕으로 구현할 수 있다. 예를 들어 다음과 같은 그림에서 각 원소는 각자의 부모를 가리키고 있지만, 실상 Find 연산을 사용하면 그 부모가 모두 똑같은 1임을 알 수 있다.
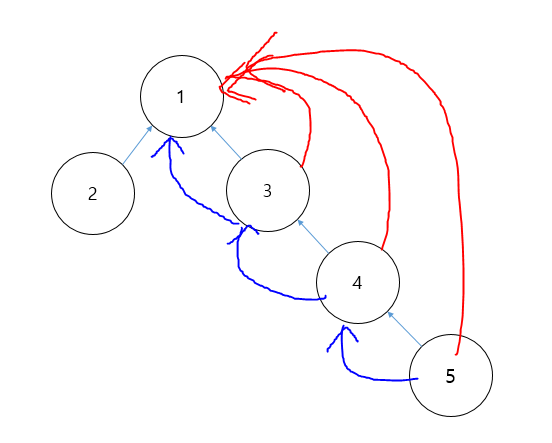
파란색 : 각 원소가 가리키는 대상(parent 배열), 빨간색 : Find 연산을 수행하면 실제로 각 원소가 가리키는 최종 부모. 따라서, 이러한 점을 활용하여 재귀를 반환(return)하는 과정에서 각 부모를 최종 부모로 바꿔주면서 반환하여 각 원소의 최종 부모를 통일 시켜준다.
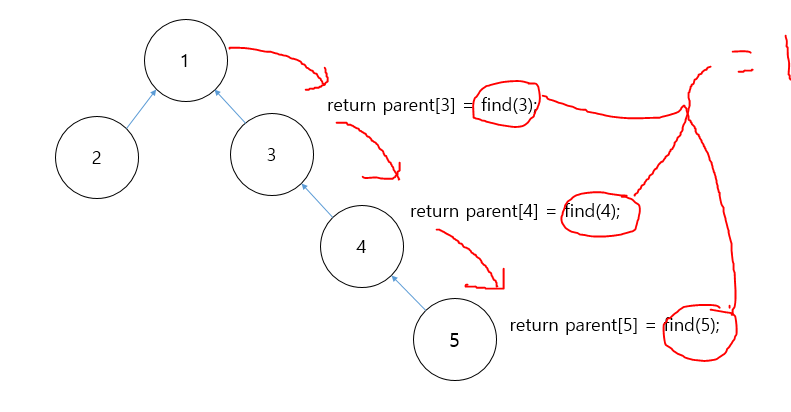
Find 연산을 반환하는 과정에서 각 부모를 최종 부모로 갱신 시켜준다. 그렇다면 트리는 최종적으로 다음과 같은 구조를 가지게 될 것이다. 다만 이 그림에서 알 수 있듯이, Find 연산은 낮은 깊이에서 탐색을 시작한다면, 더 깊은 대상은 최적화가 되지 않는다는 단점이 존재한다.(만일, 5가 아닌 3에 대해서만 Find 연산을 수행한 경우를 생각해보자).
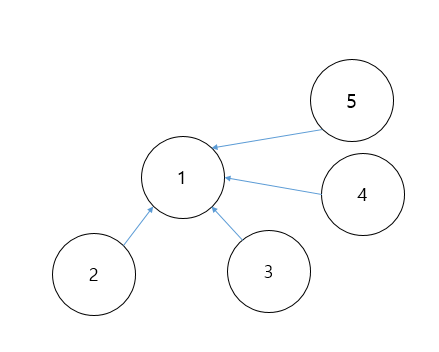
경로 압축을 통한 최종 트리 구조. 즉, find 연산를 다음과 같이 개선하여 구현할 수 있다.
private static int find(int[] parent, int x) { // 만일, 찾는 대상과 인덱스 번호가 같다면 그 인덱스(=노드)가 해당 집합의 부모이다. if (parent[x] == x) return x; // 경로 압축 else return parent[x] = find(parent, parent[x]); }이 경우 시간 복잡도를 O(α(n))까지 줄일 수 있다. 이는 사실상 O(1)의 시간복잡도와 유사하다고 생각하면 된다.
※ α(n) 이란?
-> 굳이 알 필요는 없지만, 간단히 서술하자면 여기서 α(n)는 아커만 함수의 역함수이다. 간단히 말하면 아커만 함수는 작은 입력으로 매우 큰 증가를 만드는 함수인데(우리가 아는 팩토리얼 연산보다도 더 심하다!), 이 함수의 역함수 이기 때문에, 반대로 어떤 큰 입력이 와도 작은 값을 도출할 것(보통 α(n)은 실용적으로 5보다 작다고 알려져 있다)이다. 따라서 기존 서로소 집합 연산에 비하여 더 빠른 연산이 가능한 것이다. 자세한 내용은 아커만 함수 위키백과의 '역함수' 파트를 참고하도록 하자. ko.wikipedia.org/wiki/%EC%95%84%EC%BB%A4%EB%A7%8C_%ED%95%A8%EC%88%98
아커만 함수 - 위키백과, 우리 모두의 백과사전
위키백과, 우리 모두의 백과사전. 계산 가능성 이론에서, 빌헬름 아커만의 이름을 딴 아커만 함수(Ackermann函數, 영어: Ackermann function)는 원시 재귀 함수가 아닌 전역적인 재귀 함수(계산가능 함수)
ko.wikipedia.org
※ 두 기법을 동시에 사용하는 것은?
-> 서로소 집합 연산의 성능을 향상 시키기 위한 방법이 2가지나 존재하기 때문에, 그렇다면 이 2가지 방법을 동시에 사용하면 성능이 좋지 않을까? 라는 의문을 가질 수 있다. 일리 있는 말이지만, Rank 관리 기법은 트리의 깊이를 다루는 방법이었고, 경로 압축 기법에서는 경로를 압축할 때 마다 트리의 깊이가 시시각각으로 변화하였다. 그런데 이렇게 경로압축을 통해 시시각각 변화하는 트리의 깊이를 따로 관리하고, Rank 관리 기법에 그 깊이들을 다시 활용하는 방식은 굉장히 복잡하다. 따라서 보통 두 방법 중 하나만 사용하더라도, 코딩테스트 대비 성능 면에서는 충분하다.
*총정리
-> 경로 압축 기법을 적용하고, 각 코드를 최대한 간소화 시켜 코드를 작성하면 서로소 집합은 다음과 같이 구현할 수 있다.
package pr; import java.util.Arrays; public class DisjointSet { static int[] parent; public static void main(String[] args) { // makeSet parent = new int[5]; // 각 인덱스(=노드)는 자기 자신을 가리키고 있다 parent = MakeSet(5); System.out.println(Arrays.toString(parent)); // 1이 포함된 집합, 2가 포함된 집합 합치기. union(1, 2); System.out.println(Arrays.toString(parent)); // 2가 포함된 집합, 3이 포함된 집합 합치기. union(2, 3); System.out.println(Arrays.toString(parent)); // 4가 포함된 집합, 5가 포함된 집합 합치기. union(4, 5); System.out.println(Arrays.toString(parent)); // 3이 포함된 집합, 5가 포함된 집합 합치기. union(3, 5); System.out.println(Arrays.toString(parent)); // Find 연산을 통한 각 노드가 속한 집합 확인. System.out.println(find(1)); System.out.println(find(2)); System.out.println(find(3)); System.out.println(find(4)); System.out.println(find(5)); } // Union private static void union(int a, int b) { // 각 집합을 대표하는 부모가 다른 부모로 편입 되어야 한다. 원소가 편입되어서는 안된다. a = find(a); b = find(b); // 일반적으로 더 작은 값으로 다른 집합이 편입되도록 한다. if (a > b) { parent[a] = b; } else { parent[b] = a; } } // Find private static int find(int x) { // 만일, 찾는 대상과 인덱스 번호가 같다면 그 인덱스(=노드)가 해당 집합의 부모이다. if (parent[x] == x) return x; // 경로 압축 else return parent[x] = find(parent[x]); } // makeSet private static int[] MakeSet(int size) { // 각 인덱스에 번호가 대응하도록 사이즈를 1더하여 배열 선언. int[] arr = new int[size + 1]; for (int i = 0; i < arr.length; i++) { arr[i] = i; } return arr; } }'Algorithm > 자료구조 for Algorithm' 카테고리의 다른 글
[Java]Set (0) 2022.03.22 [Java]우선순위큐(PriorityQueue) (0) 2022.03.22 [Java]덱(Deque) (0) 2021.02.18 [Java]해시맵(HashMap) (0) 2021.02.13 [Java]큐(Queue) (0) 2020.09.25